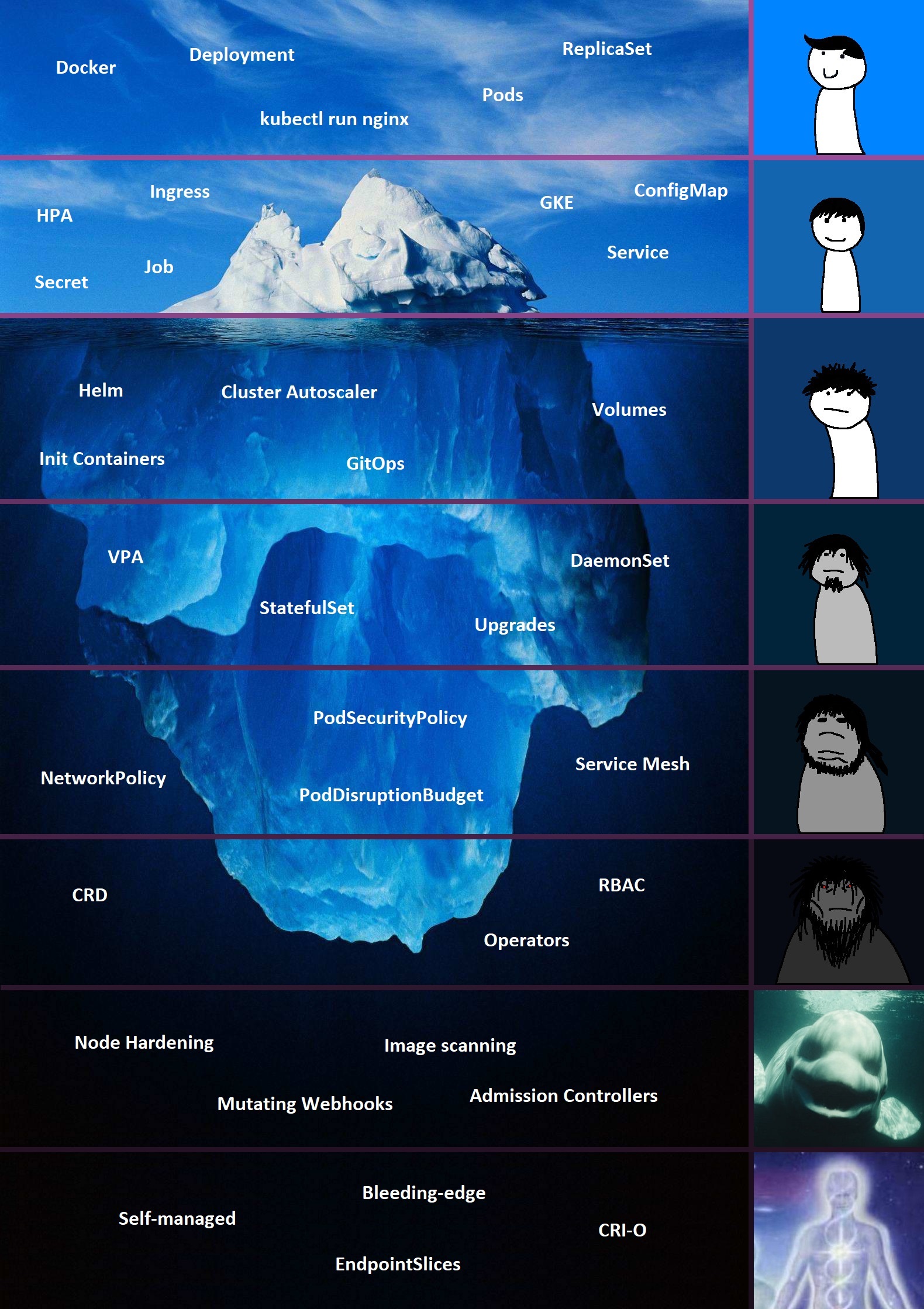
Kubernetes 101
Table of Contents
估计是继 Linux 后,目前影响最大的开源项目,概念比较多,比较复杂,文章稍长
前提准备:K8s 学习前必须要先了解容器
Docker 🐳 是继 Java 十多年之后又一个“颠覆性”的技术,接触 Docker 三年有余,过去一年多给队伍做过多次介绍
功能概述 #
Kubernetes 定义为容器编排引擎(orchestration),Kubernetes 对于容器,就相当于 Linux 内核对于线程,考虑到容器作为云基础设施上的基本运行单位,Kubernetes 就类似云上的操作系统内核,其作用包含:
集群架构 #

Kubernetes 的组件分成两组 control panel & data panel 通常相应运行在两种机器上 master node & worker node:
control panel(master node) #
master 控制节点负责管理集群,包含以下组件:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- etcd

| master |
|---|
kube-apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制,只有 API Server 会与 etcd 进行通信,其它模块都必须通过 API Server 访问集群状态。API Server 封装了核心资源对象的增删改查操作,以 RESTFul 接口方式提供给外部客户端和内部组件调用,API Server 再对相关的资源数据(全量查询 + 变化监听)进行操作,以达到实时完成相关的业务功能。 |
kube-controller-manager 负责维护各种资源对象,从现在状态(status)到用户想要的状态(spec),比如故障检测、自动扩展、滚动更新等,具体由各种 controller 负责执行: 从逻辑上讲,每个控制器都是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件并在单个进程中运行。cloud-controller-manager 用于对接各种云基础设施(AWS,Azure,GCP 等)云厂商提供接口以便让 k8s 可以管理使用其各种资源。 从逻辑上讲,每个控制器都是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件并在单个进程中运行。cloud-controller-manager 用于对接各种云基础设施(AWS,Azure,GCP 等)云厂商提供接口以便让 k8s 可以管理使用其各种资源。 |
kube-scheduler 负责资源的调度,主要用于收集和分析当前 Kubernetes 集群中所有负载节点的资源 (包括内存、CPU 等) 负载情况,并按照预定的调度策略将 Pod 调度到相应的机器上。调度策略是个比较复杂的问题,调度决策考虑的因素包括:个人和集体资源需求,硬件/软件/政策限制,亲和力和反亲和力规范,数据局部性,工作负载间的干扰,最后期限等。 |
etcd 保存了整个集群/资源的状态,是一个分布式 key-value 存储。 |
data panel(worker node) #
worker/slave 工作/负载节点运行具体的容器应用,执行并运行从 Master 传来的各种负载任务,包含以下组件:
- Container Runtime
- kubelet
- kube-proxy
- pod

| worker |
|---|
kubelet 相当于 Master 的 agent,负责和 Master 的通信,维持 Pod/容器的生命周期,同时确定其符合 YAML 所定义的 PodSpec,其中包括关于 Volume(CVI)和网络(CNI)的管理。 |
kube-proxy 负责为 Service 提供内部的服务发现和负载均衡,把 request 转发到相关容器上。 |
Container runtime 负责镜像管理以及 Pod 和容器的真正运行时(CRI),默认的容器运行时为 Docker。 |
Pod 是一组紧密关联的容器集合,它们共享 PID、IPC、Network 和 UTS namespace,是 k8s 调度的基本单位。Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。我们知道容器本质上就是进程,那么 Pod 实际上就是进程组了,只是这一组进程是作为一个整体来进行调度的。 |
此外还有非常重要的集群管理命令行客户端工具 Kubectl 通过 Kubectl 命令对 API Server 进行操作,API Server 响应并返回对应的命令结果,从而达到对 Kubernetes 集群的管理。命令主要模式:
kubectl [get|delete|edit|apply] [pods|deployment|services] [podName|serviceName|deploymentName]
Kubernetes 还有一些安装扩展才可以真正使用,包括网络 Calico/Flannel,CoreDNS,Dashboard 等,参考 安装扩展。这些组件构成了 Kubernetes 系统的物理基础,通过这些组件管理各种资源。
组件之间的通讯示意: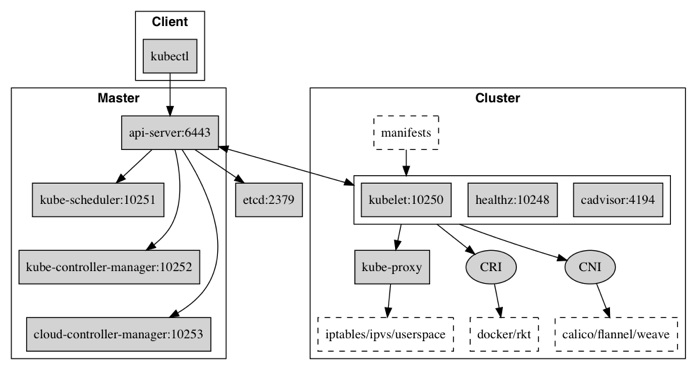
核心资源对象 #
和 OS 类似,Kubernetes 对底层静态和运行时的资源都进行了抽象,Kubernetes 的编排和管理功能就是通过对这些对象进行编排和管理
资源类别 #
| 核心资源对象类别 |
|---|
| Workload:Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job 等 |
| Networking:Service、Ingress 等 |
| Storage: Volume、CSI、ConfigMap、Secret 等 |
| RBAC:Namespace、None、Role、ClusterRole、RoleBinding、ClusterRoleBinding 等 |
| 元数据:HPA、PodTemplate、LimitRange 等 |




通过这些资源体现了 Kubernetes 的能力(能干啥事):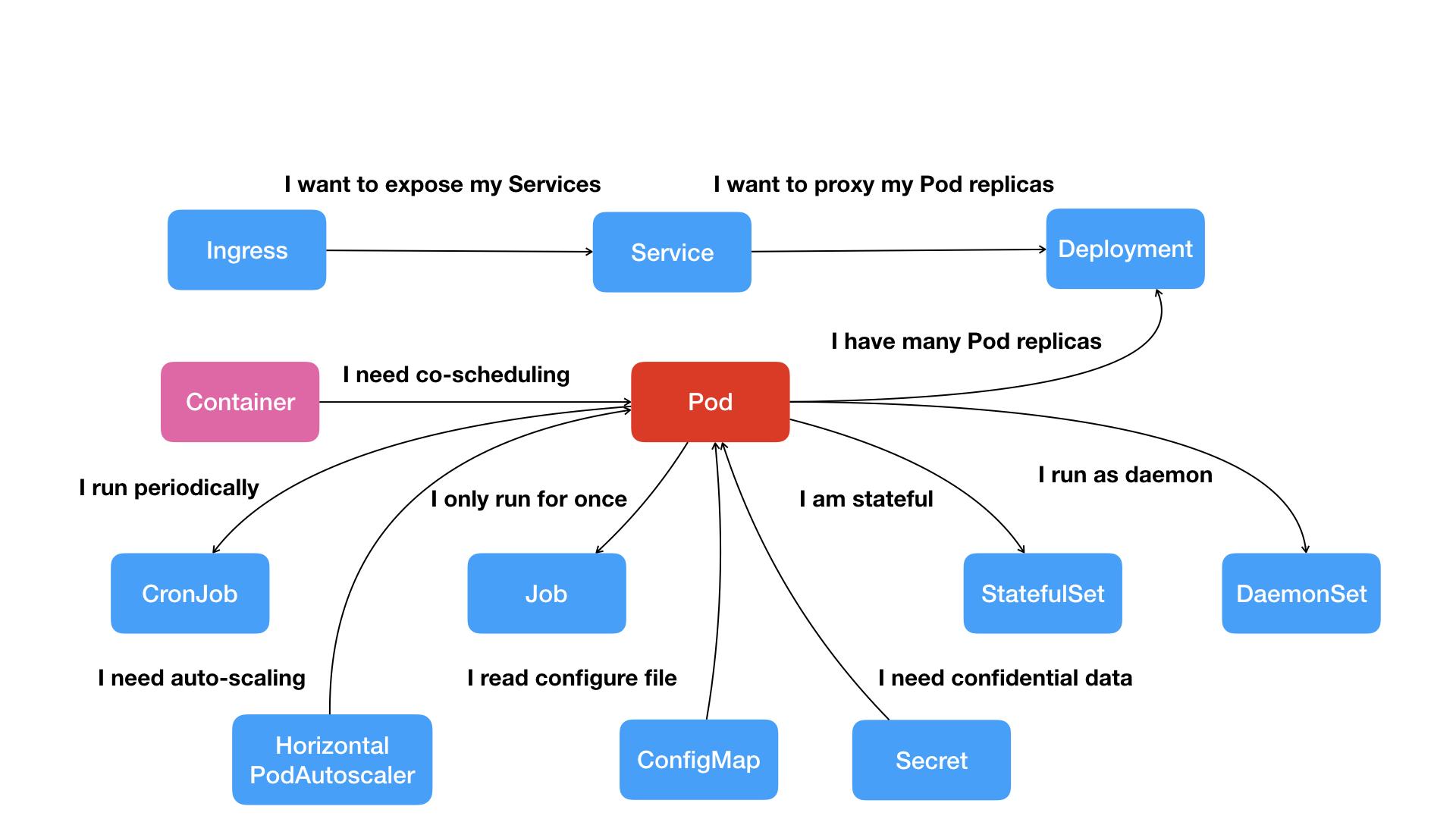
k8s 管理资源示例:
Kubernetes 的入门就是理解和使用资源对象,详细的参考文档: 使用 Kubernetes 对象 | Kubernetes
手动编辑和管理这些资源 definition file 是比较繁琐和易错的,有相应的 DevOps 工具来支撑,从学习的角度还是需要先了解一定的底层细节
(具体如何管理各种资源的原理需要大量篇幅,这里不展开)
namespaces #
k8s 把容器 namespace 的概念放大到集群规模,通过 namespace 来组织资源,一个物理 Kubernetes 集群通过 namespace 划分成几个虚拟的集群:
大部分资源对象都是具有 namespace 特性的,如果没有指定,默认 default - 同一台机器上可部署不同的 namespace 资源,它们是不相关的/相互隔离的,namespace 和 RBAC 资源管理紧密相关。有一些和 namespace 无关或者是跨 namespace 的资源 - 通常是和 cpu 算力、存储、网络相关,如 Nodes,PersisentVolumes,它们可以通过 namespace 的 Quotas 来限定。k8s 集群有三个默认的 namespace:default kube-system kube-public。
没有完美的方法来划分 namespace,可以根据需要和用途,如:
- 按项目或团队划分
- 按部署环境划分,如 dev,staging,prod
- 根据特殊要求划分,如 blue/green 部署
核心资源对象简介 #
| 抽象层 | 现实层 | 是否使用 namespace | 资源描述 |
|---|---|---|---|
| Pod | container | Pod 是 k8s 最小的负载调度单元,等同一个或多个 container(但同属于一个 container namespace) | |
| Replicaset | load balancing | 跟踪并保证指定 pod 的实例个数 | |
| Deployment | ➖ | 跟踪并保证指定 pod 和 replicaset 的配置 | |
| StatefulSet | ➖ | 加强版的 deployment,StatefulSet 是为了解决有状态服务的问题(对应 Deployments 和 ReplicaSets 是为无状态服务而设计),其应用场景包括: 1. 稳定的持久化存储,即 pod 重新调度后还是能访问到相同的持久化数据; 2. 稳定的网络标志,即 pod 重新调度后其 PodName 和 HostName 不变;3. 有序部署,有序扩展,即 pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依序进行(即从 0 到 N-1,在下一个 pod 运行之前所有之前的 pod 必须都是 Running 和 Ready 状态); 4. 有序收缩,有序删除(即从 N-1 到 0); | |
| Node | host | 运行 pod 的虚机或物理机器 | |
| Service | network | 一组相关 pods 的入口点 | |
| Ingress | reverse proxy | ingress 负责把 service 暴露到 k8s 外部 | |
| Cluster | datacenter | 一组相关 k8s 节点组成的集群,包括 master 控制节点和 worker 负载节点 | |
| Namespace | ➖ | ➖ | 在一个 k8s 集群内划分的虚拟集群 |
| StorageClass | disk | 配置存储源用以创建 PersistentVolumens | |
| PersistentVolume | disk partition | 配置文件系统,可以被挂载在 Pod 中一个或者多个容器的指定路径下面 | |
| PersistentVolumeClaim | ➖ | 把 PersistentVolume 绑定到 pod 上 | |
| ConfigMap | env var | 定义各种 properties | |
| Secret | secured env var | 加密或带有使用权限的 properties |
资源配置文件 definition file #
在 Kubernetes 中,所有资源对象都在配置文件(yaml 或 json)中定义/声明,基本格式:
apiVersion:
kind:
# 资源类别,标记创建什么类型的资源: Pod, Deployment, Job 等
metadata:
# 元数据内部是嵌套的字段
# 定义了资源对象的名称、命名空间(k8s级别的不是系统的)等、标签、注解、UID等
annotations:
name: myproj-mysql
labels: # labels recommended by k8s
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: '5.7.21'
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
app.kubernetes.io/created-by: controller-manager
data:
# 针对数据资源,如 Secret, ConfigMap
spec:
# 规范定义资源应该拥有什么样的特性,依靠控制器确保特性能够被满足,各种资源有自己的spec
# 用户定义所期望了资源状态
containers:
- name:
image:
ports:
- containerPort:
env:
- name:
value:
status:
# 显示资源的当前状态,k8s 就是确保当前状态向目标状态无限靠近从而满足用户期望
# 它是只读的,代表了资源当前状态
- Labels
labels 标签 以 key/value 的方式附加到对象上(key 最长不能超过 63 字节,value 可以为空,也可以是不超过 253 字节的字符串)。 Label 定义好后其他对象可以使用 Selector 来选择一组相同 label 的对象(比如 ReplicaSet 和 Service 用 label 来选择一组 Pod)。Label Selector 支持以下几种方式:
- 等式,如 app=nginx 和 env!=production
- 集合,如 env in (production, qa)
- 多个 label(它们之间是 AND 关系),如 app=nginx,env=test
标签对于灵活访问 K8s 资源对象非常重要,在 kubectl 可以选择或过滤 Pod:
kubectl get pods -l "app=firstapp" --show-labels
kubectl get pods -l "app=firstapp,tier=frontend" --show-labels
kubectl get pods -l "app=firstapp,tier!=frontend" --show-labels
kubectl get pods -l "app,tier=frontend" --show-labels #equality-based selector
kubectl get pods -l "app in (firstapp)" --show-labels #set-based selector
kubectl get pods -l "app not in (firstapp)" --show-labels #set-based selector
kubectl get pods -l "app=firstapp,app=secondapp" --show-labels # comma means and => firstapp and secondapp
kubectl get pods -l "app in (firstapp,secondapp)" --show-labels # it means or => firstapp or secondapp
- nodeSelector
有了 nodeSelector 我们可以指定 Pod 在哪个节点上运行:
kubectl apply -f podnode.yaml
kubectl get pods -w #always watch
kubectl label nodes minikube hddtype=ssd #after labelling node, pod11 configuration can run, because node is labelled with hddtype:ssd
- Annotations
Annotations 是 key/value 形式附加于对象的注解。不同于 Labels 用于标志和选择对象,Annotations 则是用来记录一些附加信息,用来辅助应用部署、安全策略以及调度策略等。比如 deployment 使用 annotations 来记录 rolling update 的状态。
资源实例 #
下面介绍几个核心资源具体配置实例:
- ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: simple-web-config
namespace: default
data:
configuration_key: 'Configuration value'
ConfigMap 可以通过三种方式在 Pod 中调用,三种分别方式为:设置环境变量、设置容器命令行参数以及在 PersistentVolume 中直接挂载文件或目录。
- Secret
data 默认下知识 base64 编码,不过 k8s 支持 加密或者和 role-based access control:
apiVersion: v1
kind: Secret
metadata:
name: simple-web-secrets
# Opaque can hold generic secrets, so no validation will be done.
type: Opaque
data:
# Secrets should be encoded in base64
secret_configuration_key: 'c2VjcmV0IHZhbHVl'
- Pod
apiVersion: v1
kind: Pod
metadata:
name: my-web-server
spec:
# <containers> is a list of container definition to embed in the pod
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
- Replica Set
声明 Pod 的横向水平扩展,selector 标签选择器,可以使用 matchLabels、matchExpressions 两种类型的选择器来选中目标 Pod:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myrs
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
name: myapp-pod
labels:
app: myapp # 标签一定要符合 replicaset 标签选择器的规则
release: canary
spec:
containers:
- name: myapp-containers
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
- Deployment
一般不直接管理 Pod,而是通过 Deployment 来管理应用程序。Deployment 通过控制 ReplicaSet 来实现功能,除了支持 ReplicaSet 的扩缩容意外,还支持滚动更新和回滚等,还提供了声明式的配置,这个是我们日常使用最多的控制器。它是用来管理无状态的应用。Deployment 在滚动更新时候,通过控制多个 ReplicaSet 来实现,ReplicaSet 又控制多个 POD,多个 ReplicaSet 相当于多个应用的版本。
k8s 基于 template 创建 Pod
k8s 基于 selector 创建 Replicaset,实例数目有 replicas 指定
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-server-deployment
namespace: default
labels:
app: webserver
spec:
# <selector> should retrieve the Pod defined below, and possibly more
selector:
matchLabels:
app: webserver
instance: nginx-ws-deployment
# <replicas> asks for 3 pods running in parallel at all time
replicas: 3
# The content of <template> is a Pod definition file, without <apiVersion> nor <kind>
template:
metadata:
name: my-web-server
namespace: default
labels:
app: webserver
instance: nginx-ws-deployment
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
- Service
由于 Pod 可以被动态创建,所以其提供的服务不能通过其 ip 地址直接访问。Service 为 Pod 控制器控制的 Pod 实例提供一个固定的访问端点 - 一个 k8s 集群内部的虚拟 ip,集群内部通过虚拟 ip 访问一个服务,负载均衡由 Kube-proxy 实现。Service 的工作还依赖于一个安装扩展,就是 CoreDNS ,它将 Service 地址提供一个域名解析。组成 Service 的 Pod 由 selector 里的 lables 来选定。
有三种 service:
ClusterIP:在集群内部 IP 上公开服务,选择此值使得服务只能从集群内部访问,默认方式
NodePort:把 Service 绑定在 Pod 所在节点的一个静态端口 Node Port(30000-32767),NodePort 服务到 ClusterIP 服务的路由会自动创建。这样能够从集群外部联系 NodePort 来请求服务(由于要公开 Node Port,这种 Servide 会带来安全隐患)
LoadBalancer:使用云提供商的负载均衡器向外部公开服务,负载均衡器到 Node Port 或 ClusterIP 服务的路由是自动创建的
ExternalName:通过返回 CNAME 记录及其值,将服务映射到 externalName 字段的内容(例如 foo.bar.example.com)
apiVersion: v1
kind: Service
metadata:
name: simple-web-service-clusterip
spec:
# ClusterIP is the default service <type>
type: ClusterIP
# Select all pods declaring a <label> entry "app: webserver"
selector:
app: webserver
ports:
- name: http
protocol: TCP
# <port> is the port to bind on the service side
port: 80
# <targetPort> is the port to bind on the Pod side
targetPort: 80
了解 Service 需要先了解 K8s 网络如何工作。
K8s 网络 #
K8s 自身的网络设计:
- 每个 Pod 都有唯一的、自己的 IP 地址(Pod 内的容器共享网络命名空间)
- Pod 的 IP 在整个集群中是唯一的
- 所有 Pod 都可以与所有其他 Pod 通信,无需 NAT(网络地址转换)
- 所有 Node 都可以与所有 Pod 通信,无需 NAT
不同供应商和设备的容器和节点的联网很难处理。因此,K8s 将这个责任交给了 CNI(Container Network Interface 容器网络接口) 来处理网络需求。CNI 是一个云原生计算基金会项目,由用于编写插件以在 Linux 容器中配置网络接口的规范和库组成,以及许多受支持的插件。用户选择的 CNI 插件包括:Flannel,Calico,Weave, 和 Canal,其中 Calico 是比较流行的开源 CNI 插件之一。
部署资源 #
资源对象配置文件定义好后,就可以通过 kubectl 来管理
# <kind> is the type of resource to create (e.g. deployment, secret, namespace, quota, ...)
$ kubectl create <kind> <name>
$ kubectl edit <kind> <name>
$ kubectl delete <kind> <name>
# All those commands can be used through a description file.
$ kubectl create -f <resource>.yaml
$ kubectl edit -f <resource>.yaml
# create & update
$ kubectl apply -f <resource>.yaml
$ kubectl delete -f <resource>.yaml
| 更新和回滚 |
|---|
| maxUnavailable:在更新期间,显示删除的容器的最大数量(总计:10 个容器;如果 maxUn:2,则该时间段内运行的最小:8 个容器) |
| maxSurge:在更新期间,显示集群上运行的最大容器数(总计:10 个容器;如果 maxSurge:2,则一次最多运行 12 个容器) |
| 重新创建策略:先删除所有 Pod,然后从头创建 Pod。如果两个不同版本的软件相互产生负面影响,则可以使用此策略。 |
| 滚动策略(默认):逐步更新 Pod。Pod 是逐步更新的,所有 Pod 不会同时删除。 |
kubectl set image deployment rolldeployment nginx=httpd:alpine --record # change image of deployment
kubectl rollout history deployment rolldeployment #shows record/history revisions
kubectl rollout history deployment rolldeployment --revision=2 #select the details of the one of the revisions
kubectl rollout undo deployment rolldeployment #returns back to previous deployment revision
kubectl rollout undo deployment rolldeployment --to-revision=1 #returns back to the selected revision=1
kubectl rollout status deployment rolldeployment -w #show live status of the rollout deployment
kubectl rollout pause deployment rolldeployment #pause the rollout while updating pods
kubectl rollout resume deployment rolldeployment #resume the rollout if rollout paused
内部架构 #
Kubernetes 虽然庞大复杂,但是其架构和设计机理却是很清晰。

| 分层 & 插件架构 |
|---|
| 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境 |
| 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等) |
| 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等) |
| 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦 |
| 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴 - Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等 Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等 |
核心组件:
生态系统架构:
Kubernetes 以及云原生 #
以 Kubernetes 为基础成长的云原生生态: Cloud Native Landscape
技术是生产力发展的核心,发生第二次工业革命是因为有了蒸汽动力等技术的出现,发生 Internet 是因为有了 HTML,CSS,Tcp/Ip 等技术,发生 digital transformation 是因为有了 Kubernetes 等云原生技术,其中的一些显著特点:
轻量级的容器技术
不依赖底层 infrastructure 或服务,包括 OS,VM,物理机器,以及各种云基础设施
声明式资源管理
按需自动弹性扩展
拥有强壮性和自愈功能
编程语言无关
API 驱动
Stateless/Stateful 应用分离
微服务架构
敏捷和自动化 DevOps
自服务
云原生众说纷纭,我的看法就是容器和 Kubernetes,因为还未看到有第二种技术来实现支持上述特性。
Kubernetes 相当一个云操作系统内核,内外沿涉及到的东西几乎是个无底洞,不是 3-5 个小时或 3-5 天就能搞定,慢慢来。