Ansible 从入手到上手 🚀🚀🚀
Table of Contents
Ansible,运维工具里的瑞士军刀,简单、粗暴,一文快速上手到项目最佳实战
很多人会告诉你自动化工具(automation)不是 DevOps,但他们没有告诉你什么是 DevOps 的核心,如果你把自动化(automation)从他们的表述中除去,你看看 DevOps 还是什么呢。Ansible 从核心上讲,就是一个可编程的 automation 框架,通过各种扩展,完成运维里各式各样的脏活累活,如创建用户,安装配置软件,等。
Why Ansible #
做 IT 的的都知道,除了设计,写代码,离不开装机器,装软件,装系统,原始的办法是手动安装和配置,但对于一个大型项目、产品或系统:
- 需要装很多次(1000+)
- 需要在很多机器上装(1000+)
- 需要在不同的环境和不同的 OS 上装
- 需要为不同的客户定制安装
- 如果是手工行为,步骤超多,如何防止人为疏忽
- 安装、运维文档如何更新,维护
最原始的解决办法就是写脚本,尽量自动化,让机器来替我们干活 - 机器不累,不出错。但如何写出没有错,可复用,可叠加的脚本呢 ⏤ 脚本语言就比较难胜任了。这就是为什么需要 Ansible,它的核心完成两个最基本的事情:
配置管理 configuration or change management:Ansible 不是专门的配置管理系统 CMDB(configuration management database),但没有这些配置信息无法干活啦,一般软件项目需要的基础配置也就是 ip, hostname, 环境变量,config file, password,等等。Ansible 能够提供配置管理,但更像是 CMDB 的执行者,把配置实现到机器上。Ansible 可以和 各种 CMDB 实时结合工作,达成配置动态收集,动态更改,动态实现,这个“高级”用法就不在本文讨论范围。
自动化框架 automation framework:注意不只是 automation,这里其实包含了几重意思:
- Ansible 是用 Python 实现的,可以干几乎任何编程语言能干的事情,所以是可编程的自动化框架,实现自动化的扩展和重用,Python 是一种超级”胶水“语言,贴近自然语言,运维二次开发非常容易;
- Ansible 使用上采用类似 SQL“声明式”的 命令(yaml),而不是一大段具体的自动化动作细节,关注点在“What”上而不是“How”,这是自动化层面的抽象,有别于脚本,使用者也不必纠缠于五花八门的命令行用法细节;
- ssh instead of agent:ssh,Python 在 Linux 几乎所有的版本上自带,所以 Ansible 的使用依赖几乎为 0(唯一问题是诞生之初不考虑 Windows,最近才支持);
- Ansible 没有像 Chef、Puppet 那样复杂,二次,三次,四次抽象的概念和架构,有运维知识,1,2 小时基本就可上手,Ansible 贴近 shell/Linux 原生系统,一条 Ansible 命令影响成百上千台机器,任何复杂系统的配置包装一下就可以融入 Ansible,简单粗暴,但非常灵活,对于运维这种千奇百怪的脏活、累活,超级耐操;
- 编排自动化的动作(orchestration:把几个事情串在一起执行像交响乐演奏需要各种乐器的一起配合),这样才能完成用户特定的复杂事情,这就比脚本和脚本库高一个档次;
在 IT 界,重复发明轮子的事多了去,Ansible 也属于此,但和老牌的 Chef、Puppet 相比,优势在于易用、好用、耐用。
YAML 标记语言 #
Ansible 的主要工作都是通过编写 YAML 文件完成的。YAML,一种标记语言,Python 社区发明的,现在广泛采纳用来写配置 template,和 Json、XML 类似。Json 可以说是完全极其抛弃臃肿的 XML,YAML 则是以 Json 的基础,更为简练,同时加入更为丰富的表达,如可以有 comment,比较一下:

YAML 语法以健值对为基础,可以表达散列表、标量等数据结构,结构通过空格和新的一行来展示,文件扩展名为 yml 或 yaml。YAML 简单直观,非常容易理解。
| 语法注意 |
|---|
| - 大小写敏感 |
| - 使用缩进表示层级关系 |
| - 缩进时不允许使用 Tab 键,只允许使用空格 |
| - 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 |
| - 基本数据类型:支持整型、浮点型、时间戳类型、布尔(true/false,yes/no)、字符串等基本数据类型 |
| - 序列(数组)里配置项通过 - 来代表 |
| - 序列(数组)的元素是 Primary(字符串,数值,布尔)可以用 [] 来表示 |
| - 多个健值对可构造成复杂结构(Object),如上图所示的 microservices 数组元素 |
| - 键值用 : 来分隔 |
| - 注释用 #,没有多行注释 |
| - 字符串可以用‘或“来包裹,也可以完全不用,特殊字符则用 \ 表达,如换行符 \n |
| - 多行字符串用 | 打头 |
| - 通过 \$xxx 来引用环境变量 xxx |
| - 动态值用 {{ }} (placeholder)来表示 |
下面是个例子(Ansible 的 playbook):
---
- hosts: webservers
vars:
http_port: 80
max_clients: 200
remote_user: root
tasks:
- name: ensure apache is at the latest version
yum:
name: httpd
state: latest
- name: write the apache config file
template:
src: /srv/httpd.j2
dest: /etc/httpd.conf
notify:
- restart apache
- name: ensure apache is running
service:
name: httpd
state: started
handlers:
- name: restart apache
service:
name: httpd
state: restarted
工作原理和基本概念 #
Ansible 从一个管理节点(management node)上通过 ssh 发送命令(Python 程序)到各个机器上执行,基本执行原理可以用下面这张图概述:
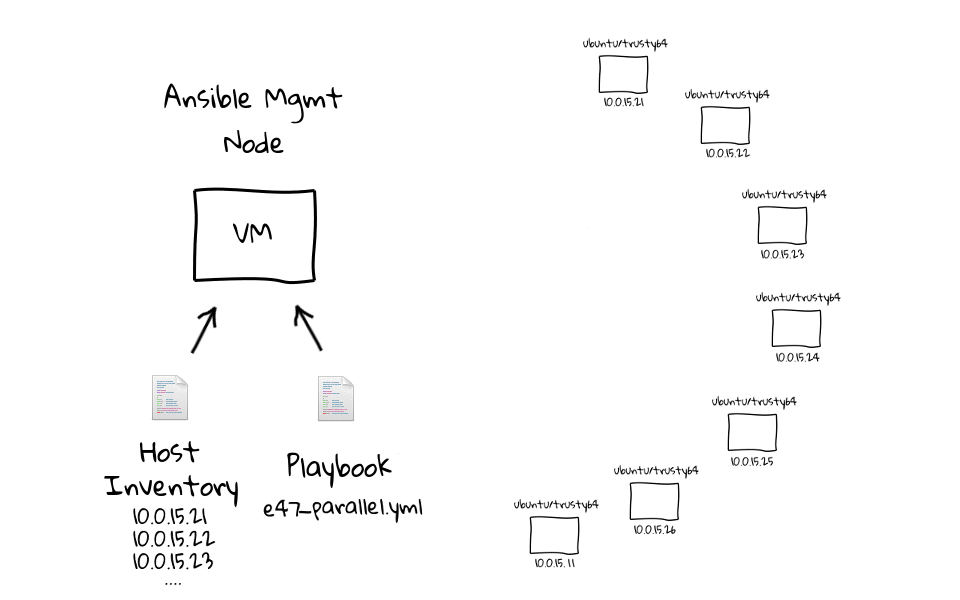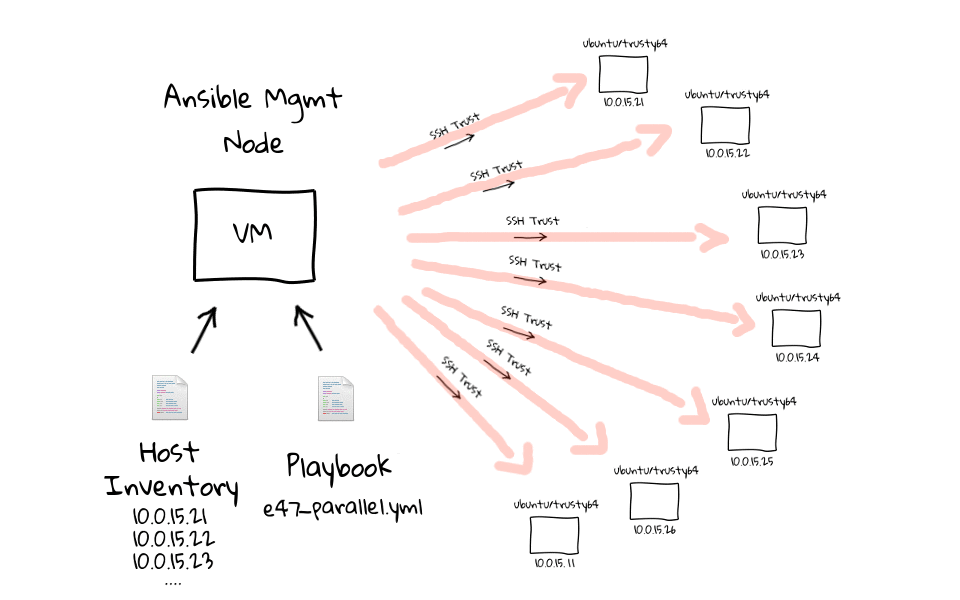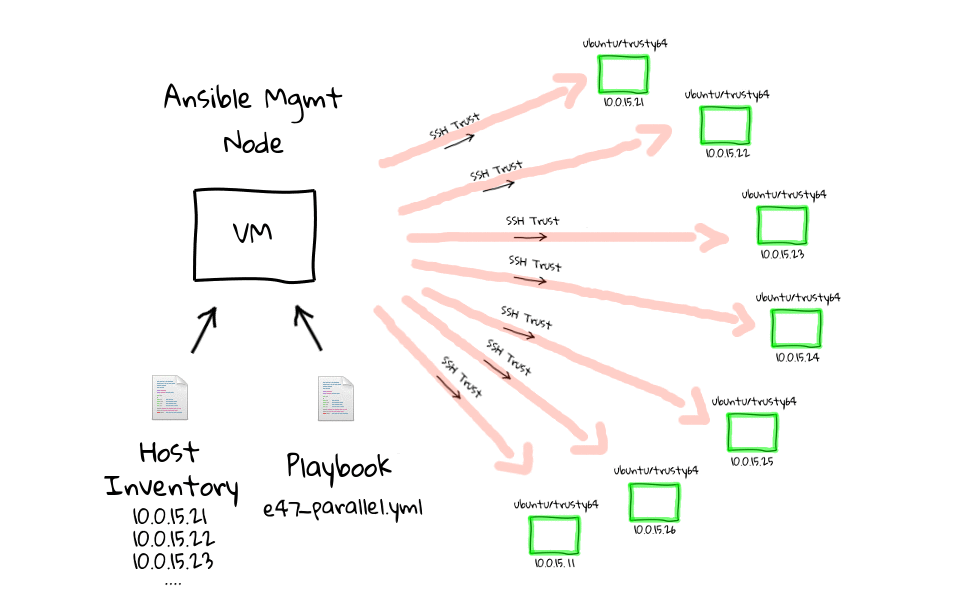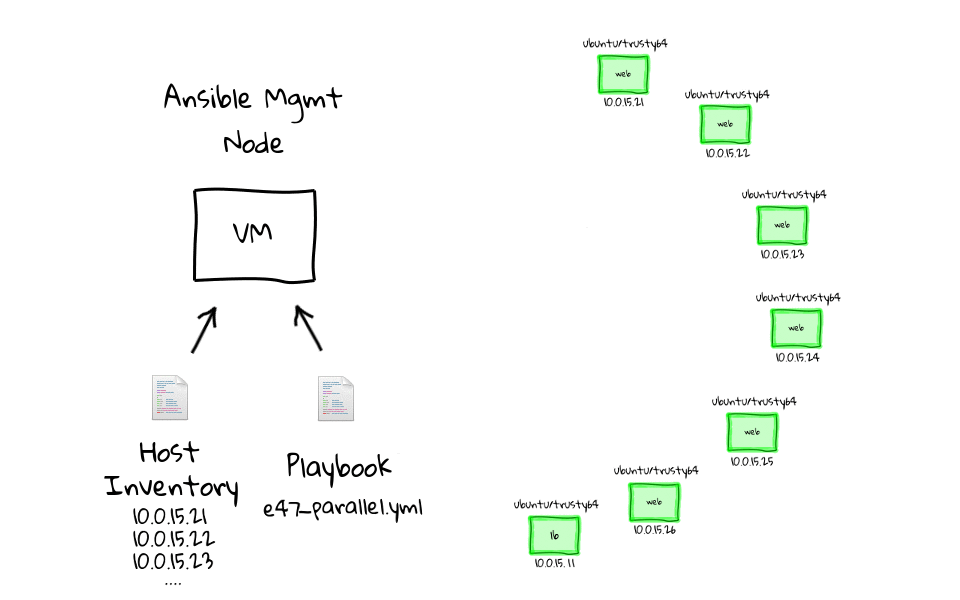
图中包含了 Ansible 的基本概念:
| 基本概念 | |
|---|---|
Ansible Inventory | 定义目标机器,程序在哪里执行 |
Ansible Modules | Ansible 自带或自己扩展的程序,运行后达到一定的作用/目的 |
Ansible Playbook | 指示如何执行 Modules,把 Inventory 和 Modules 连接在一起 |
inventory #
inventory 以 一个或多个 YAML 文本文件形式存在(非标准 YAML),可定义机器的信息(也称为机器变量),包含 主机名、ip、端口、登录用户名 等。执行时通常要给 Ansible 指定一个 inventory 。动态机器信息 或外部 inventory 不在这里讨论。
编写 inventory 也是个技巧,下面 inventory 的例子定义了 dev 环境中的机器:
localhost ansible_connection=local
myapp-db1 ansible_ssh_host=172.16.0.62
myapp-db2 ansible_ssh_host=172.16.0.63
myapp-app1 ansible_ssh_host=172.16.0.60
myapp-app2 ansible_ssh_host=172.16.0.61
myapp-web1 ansible_ssh_host=172.16.0.64
myapp-web2 ansible_ssh_host=172.16.0.66
[dev:children]
myapp-dbs
myapp-apps
myapp-webs
[myapp-dbs]
myapp-db1
myapp-db2
[myapp-apps]
myapp-app1
myapp-app2
[myapp-webs]
myapp-web1
myapp-web2
[dev:vars]
ansible_ssh_user=ansible
ansible_ssh_private_key_file="/home/ansible/.ssh/id_rsa"
myapp-db1 ansible_ssh_host=172.16.0.62
定义了 myapp-db1 这台机器 host,ansible_ssh_host 是系统变量名,用来定义此台机器的 IP 地址(其实是隶属于 myapp-db1 的一个 key),自己可以加入自定义的变量。
[dev:children]
children 这个关键字说明 dev 的成员 myapp-dbs 和 myapp-apps 不是单个 host,而是一个组,[myapp-dbs] 和 [myapp-apps] 则分别定义了他们的组成员
[dev:vars]
vars 这个关键字说明里面的变量将作用在所有的 dev 成员上(dev 的通用变量),ansible_ssh_user 和 ansible_ssh_private_key_file 也都是系统变量名。
task & module #
task & module - task 就是最小执行单位(类似编程里的方法),module 模块就是提供一组相关的 task(类似编程里的类或者包)。Ansible 提供的 task 接近 2000 个(linux shell 的命令基本都用 Python 实现了),核心模块超过 400 个,运维需要的东西基本都包括了,具体见 Ansbile Module 文档。自己也可以通过 Python 扩充任务模块( 编写自己的模块),这个也不在本文讨论范畴,现有的模块已经基本够用了。
playbook #
playbook 也是 yaml 文本文件存在,类似于编程中你自己开发的程序,把不同的 task 串联在一起(类似调用不同的方法和类),完成你想要的事情。
编写 playbook 是使用 Ansible 进行运维的主要工作,playbook 里定义了一系列的 tasks,每一段包含下面的一些核心元素:
| 名称 | 含义 |
|---|---|
| name | 任务组名称或描述 |
| hosts | 目标机器 |
| become,become_user | 指定登录执行任务的用户名,目标机器和执行任务的用户可能不同,例如执行某些任务需要 root 权限 |
| tags | 任务标签,可用于选择选择性执行 |
| Tasks | 任务集,一组具体操作,可以调用某个或多个任务模块(task module)、某个或多个角色(task role)来完成 |
| Varniables | 变量,内置变量或自定义变量在 playbook 中调用 |
| Templates | 模板,即使用模板语法的文件,比如配置文件等 |
| Handlers | 处理器,和 notity 结合使用,由特定条件触发的操作,满足条件方才执行,否则不执行 |
| Roles | 角色,可以重复调用 |
一个例子:
#!/usr/bin/env ansible-playbook
# provision-dbs.yml
- name: set fact-related variables (always run)
hosts:
- myapp-dbs
gather_facts: true
tags: always
tasks:
- include: vars.yml
- name: db server common
hosts:
- myapp-dbs
become: true
roles:
- { role: server-common, tags: ['common'] }
- name: install & config mongodb
hosts:
- myapp-db1
become: true
roles:
- { role: mongodb, tags: ['mongodb'] }
- name: install & config mysql
hosts:
- myapp-db2
become: true
roles:
- { role: mysql, tags: ['mysql'] }
role #
| role 组成: | |
|---|---|
| defaults | 定义该 role 用到默认变量,该 role 运行时自动加入这里定义的变量,但其定义的变量优先级别最低,若已在其他地方定义,可被覆盖 |
| vars | 该 role 运行时自动加入这里定义的变量,通常可把需要传入的变量定义在这里,vars 和 defaults 很类似,通常把必须用到变量的放在 defaults 里,可变的放在 vars 里,例如 tasks 里针对不同的 OS,版本用到的变量,需要到的时候可以引入,include_vars 可自动在此目录中寻找变量文件(相对路径) |
| files | 存放各种文件,该 role 需要执行相关 file tasks 时,file module 可自动在此目录中寻找文件(相对路径) |
| templates | 该 role 需要执行 template task 时,可自动在此目录中寻找 template 文件(相对路径),template 这个 task 专门用来修改配置文件 |
| tasks | 该 role 需要执行的 tasks,类似 playbook,include 可在此目录中寻找 tasks 文件(相对路径) |
| handlers | 定义该 role 需要的回调 task,在 tasks 里可以调用 |
role 类似你自己已经开发好的一个小程序,完成固定的功能,可以重复使用。你也可以直接使用社区里别人开发和分享的 role。社区里包含大量的 role,基本上你想做的事情都有人实现了,或者把 source code 拷下来,自己稍微修改,顺便学习如何编写自己的 role: 一个安装和配置 mysql 的 role。
playbook 级别可以用 role: 来调用 role,task 级别可以用 import_role: 或者 include_role: 来调用 role
在运行时,Ansbile 把 playbook 结合 inventory 和 module/roles 编译成 Python 程序,managed node 通过 SSH 将其发送至目标机器,然后在目标机器上执行。 Ansible 把目标机器看成是一个状态机,每做一个 task,状态会发生改变,通过若干 task 后,目标机器就从原始状态达到你想要的状态,实现“状态变化管理”。如果目标机器已经处于目标状态中,该 task 就不会被执行。每一步变化是“等幂”的 - 可重复,可验证。

task,module,playbook,role 这些概念结合 Ansible 实际例子一看就会明白。
项目实战 #
项目模版 #
快速实战必读: Best Practices
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
library/ # if any custom modules, put them here (optional)
module_utils/ # if any custom module_utils to support modules, put them here (optional)
filter_plugins/ # if any custom filter plugins, put them here (optional)
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/ # this hierarchy represents a "role"
tasks/ #
main.yml # <-- tasks file can include smaller files if warranted
handlers/ #
main.yml # <-- handlers file
templates/ # <-- files for use with the template resource
ntp.conf.j2 # <------- templates end in .j2
files/ #
bar.txt # <-- files for use with the copy resource
foo.sh # <-- script files for use with the script resource
vars/ #
main.yml # <-- variables associated with this role
defaults/ #
main.yml # <-- default lower priority variables for this role
meta/ #
main.yml # <-- role dependencies
library/ # roles can also include custom modules
module_utils/ # roles can also include custom module_utils
lookup_plugins/ # or other types of plugins, like lookup in this case
webtier/ # same kind of structure as "common" was above, done for the webtier role
monitoring/ # ""
fooapp/ # ""
当然此模版有瑕疵,看下面的重点。
四部曲 #
如何编写和组织 inventory,role,playbook 是 Ansible 自动化实施的主要工作内容,我总结了这个四部曲的套路:
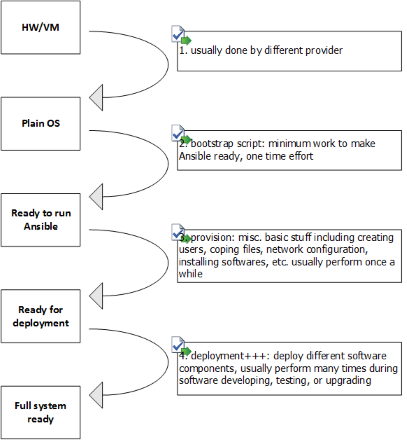
3,4 由 Ansible 完成,所以通常我会有两个对应 playbook ⏤ sys.yml 和 site.yml:
#!/usr/bin/env ansible-playbook
# sys.yml
- name: display environment name
hosts: localhost
tags: always
tasks:
- debug:
msg: 'MyApp environment >>> {{ app_env }}'
- name: display environment name
hosts: localhost
tags: always
tasks:
- debug:
msg: 'MyApp OS >>> {{ ansible_os_family }}'
- include: sys-dbs.yml
- include: sys-apps.yml
- include: sys-webs.yml
#!/usr/bin/env ansible-playbook
# site.yml
- name: display environment name
hosts: localhost
tags: always
tasks:
- debug:
msg: 'MyApp environment >>> {{ app_env }}'
- name: display environment name
hosts: localhost
tags: always
tasks:
- debug:
msg: 'MyApp OS >>> {{ ansible_os_family }}'
- include: site-cots.yml
- include: site-apps.yml
- include: site-misc.yml
重点:变量 vars #
运维的复杂性和灵活性由变量(vars)来体现的,Ansible 的 var 可在多处定义,并有 优先顺序。不过不用那么复杂,关键是搞清楚变量应用的范围:
全局变量vars/main:不受部署环境影响,到处都要用到,全局变量的例子比如 project_name, app_user,db_port, 等等。环境变量env_xxx/group_vars/all/xxx:项目开发中通常有多个环境 xxx:local, dev, stag, uat, prod,有些变量随环境改变而改变,但相当于该环境下的全局变量,除了 inventory/机器变量外,其它的变量例子如 host file, resource_dir,repo_url,等等。
Ansible 没有提出全局变量和环境变量的使用和区别,只有 机器变量 group_vars & host_vars,Ansible Best Practices 里把它们当做了全局变量,但结构上是支持的,也就是每个环境下都可以分别有 inventory 和 group_vars & host_vars,而 all 就是默认的机器组,所以 env_xxx/group_vars/all/下所有的变量文件都会被识别为机器全局变量,而且 all 的机器变量引用时不需要前缀指定,特定的 group_vars & host_vars 变量 xxx 必须指明是哪个 group {{ groups[“dbs”].xxx }} 或 host{{ hostvars[“db1”].xxx }},“groups”和“hostvars”是 Ansible 内置变量。为了支持全局变量(各个环境都使用),可以通过 file link 的方法让每个 env_xxx/group_vars/all/main 指向同一个文件,上图中的 env_dev/group_vars/all/main 指向 vars/main。
支持多 OS,多基础设施的变量:这种变量主要是支撑产品级的软件项目,通常是动态的,通过任务执行来设定,例如上面的 dbservers.yml 里引用的 vars.yml:
- name: define os family (suse) set_fact: os_family: 'suse' when: ansible_os_family == "SuSe" - name: define os family (redhat) set_fact: os_family: 'redhat' when: ansible_os_family == "RedHat" - name: define os family (debian) set_fact: os_family: 'debian' when: ansible_os_family == "Debian" - name: check os_family fail: msg: 'ERROR - can not detect supported os_family' when: os_family is not defined变量 os_family 在以后的 tasks 和 roles 中都可能用到。
role 变量:这些变量应用范畴只是该 role,是传统意义上各软件 component 的参数变量,在 role 里定义和使用,但 playbook 调用时可以进行指定或覆盖默认值,例如一个 Tomcat 的 war 部署时传入 war_name:
- name: deploy my app1 hosts: - myapp-apps become: true become_user: '{{ app_user }}' roles: - { role: tomcat-deploy, war_name: 'app1', tags: ['app1'] }Ansible 流程和控制变量:上面的变量主要用来支持配置的,还有一些属于控制或者辅助控制 Ansible 流程的,这些通过 Ansible 提供的功能来指定,例如从命令行输入:
- name: create app user name & password hosts: all become: true become_user: root vars_prompt: - name: app_user prompt: "app user name: " - name: app_password prompt: "app password: " - name: app_group prompt: "app group: " user: name: "{{ app_user }}" password: "{{ app_password }}" group: "{{ app_group }}" append: yes generate_ssh_key: yes shell: /bin/bash home: "/home/{{ app_user }}" createhome: yes state: present流程控制变量的例子见下面。
Ansible 默认/内置变量:例如 {{ playbook_dir }} 获得当前运行的 playbook 路径, {{ role_path }} 则是当前 role 的路径,这里有个 非常好的参考
重点:标签 tags #
在调试和部署的时候,有些任务需要重复多次的,而 playbook 包含从头到尾全部的操作,所以需要指定特定的任务(过滤掉其它的),这时候标签(tags)发挥作用。Ansible 命令行支持两种标签指定方式:
- -t or --tags
- --skip-tags
怎么打标签关键是看需要做什么样的动作,例如 provision-dbs.yml 里:
- name: db server common
hosts:
- myapp-dbs
become: true
roles:
- { role: server-common, tags: ['common'] }
如果指定标签 common,就可以执行所有 common 的任务。而在 common 这个 role 的 tasks 里:
- include: repo.yml
tags: repo
- include: hostfile.yml
tags: hostfile
- include: misc.yml
如果我在命令行里指定标签 hostfile,这样就能执行部分特定的 common 任务。通过不同标签的组合也可以完成一定的任务,例如用于升级系统的 tomcat:
> play appservers.yml -t tomcat,app1
标签 tag 最终是落在每一个 task 上的(透过 playbook,role),但直接给每个 task 打标签就很麻烦,为保持 role 的可移植,我基本不在 role 里打标签。我遇到了 playbook 的 include 打上标签,但不起作用(Ansible bug or defect?)。
有的时候 tags 还是不好用,例如 mysql 里要不要做 clustering,这时可以通过变量来控制,参考下面的 “有条件执行”。
基本操作和技巧 #
安装 #
Ansible 只安装在 management node 上,安装 Ansible 通过 Linux 上各种包安装工具如 RedHat 的 yum,Suse 的 zypper,Mac 的 brew 等,很容易搞定),如果 offline 安装,手动安装所需要的 rpm。由于 Ansible 是 Python 编写的,所以也可以用 pip 来安装。具体参见: 官方安装文档。
Ansible 的目标机器可以是 Linux 或 Windows,但目前 management node 必须是 Linux,虽然有各种 hack,但强烈不建议 Windows 作为 management node。
设置 #
Ansible 的设置文件可以按顺序下面找到:
1. \$ANSIBLE_CONFIG
2. ./ansible.cfg
3. ~/.ansible.cfg
4. /etc/ansible/ansible.cfg
下面是 ansible.cfg 例子:
[defaults]
forks = 5
host_key_checking = False
gathering = smart
roles_path = /usr/local/repository/ansible/roles
[priviledge_escalation]
become_method = sudo
[ssh_connection]
ssh_args = -o ForwardAgent=yes
scp_if_ssh = True
pipelining = True
执行 #
Ansible 的运行有两种主要模式,一种是 playbook 模式,另一种是随机模式。
playbook 例子,一个命令把整个系统搞起:
> ansible-play site.yml
随机例子 1,执行某个命令行"service status-all":
> ansible db1 -a 'service --status-all' -u ansible -b
随机例子 2,执行某个 task module(shell),通过 -a 输入该 task module 附加参数,效果和上面一样:
> ansible db1 -m shell -a 'service --status-all' -u ansible
当然 playbook 是主要模式。
gathering facts #
在 ansible.cfg 中加入:
gathering = smart
fact_caching = jsonfile
fact_caching_connection = /app/myapp/deployment
fact_caching_timeout = 86400
可以收集机器信息,并放入缓存,大大加快每次执行的速度。
过滤 host #
除了 tags,可以通过 -l 来限定目标机器,Ansible 支持比较复杂的机器组合方式:
- OR 关系: h1:h2
- NOT 关系: !h1
- Wildcard: web*.app.com
- Regx: (~web[0-9]+)
通过 -t 和 -l 就能指定在 {某个目标机器} 做 {某个动作},例如只在 db1 这台机器上执行 mysql:
> play dbservers.yml -t mysql -l db1
SSH Keys #
通过 key 免去登录密码输入,有几种选项:
- 一个 key 登录所有机器,通过默认的 key 实现,在 ansible.cfg 文件里的 defaults 定义:
private_key_file=/etc/ansible/keys/access.pem
- 一个 key 登录一组机器,例如在上面的 inventory 文件里:
[dev:vars]
ansible_ssh_user=ansible
ansible_ssh_private_key_file="/home/ansible/.ssh/id_rsa"
- 一个 key 登录一台机器, 也是在在上面的 inventory 文件里定义:
myapp-db1 ansible_ssh_host=172.16.0.62 ansible_ssh_private_key_file=/etc/ansible/keys/db1.pem
myapp-db2 ansible_ssh_host=172.16.0.63 ansible_ssh_private_key_file=/etc/ansible/keys/db2.pem
myapp-app1 ansible_ssh_host=172.16.0.60 ansible_ssh_private_key_file=/etc/ansible/keys/app1.pem
myapp-app2 ansible_ssh_host=172.16.0.61 ansible_ssh_private_key_file=/etc/ansible/keys/app2.pem
- 让 SSH/SSH-Agent 自己去解决
有条件执行 #
register, when, changed_when, failed_when 例子:
- name: install jdk rpm (suse)
shell: zypper -n in {{ java_rpm }}
when: os_family == "suse"
register: install_java
changed_when: install_java.rc == 0 and "already installed" not in install_java.stdout
- name: validate java home
shell: . /etc/profile && echo $JAVA_HOME
register: java_home_result
failed_when: java_home_result.stdout is not defined or java_home_result.stdout
有些配置只需要做一次,例如数据库初始化,虽然 Ansible 提供了 run_once,但感觉不好用,还是直接用变量做开关来控制。
循环执行 #
下面的例子循环构建所有的 docker image:
# docker-build.yml
- name: build all service docker images
host: app-build
become: true
tasks:
- name: build a docker image
include_role:
name: docker-build
vars:
- image_name: '{{ item.name }}'
- image_tags: '{{ item.tags }}'
with_items: '{{ service_images }}'
when: (includes is not defined) or (item.name in includes)
Ansible 通过 with_items、with_dict 等达到循环的目的,上面的例子还加入命令行动态变量 includes 来控制指定的 image:
# play docker-build.yml -e "includes=[service1, service2]"
多重循环:
- name: build all service docker images
host: app-build
become: true
tasks:
- name: build a docker image
include_role:
name: docker-build
vars:
- module_name: '{{ item.0.name }}'
- image_name: '{{ item.1.name }}'
- image_tags: '{{ item.1.tags }}'
with_subelements::
- “{{ modules }}”
- service_images
when: (includes is not defined) or (item.0.name in includes)
item.0 和 item.1 对应循环体的循环变量。
ansible-vault 存储敏感信息 #
密码等属于敏感信息,可以把包含敏感信息的文件通过 ansible-vault 加密,加密后的文件看起来就像乱码而非明文,例如:
> cat password.txt
$ANSIBLE_VAULT;1.1;AES256
66633936653834616130346436353865303665396430383430353366616263323161393639393136
3737316539353434666438373035653132383434303338640a396635313062386464306132313834
34313336313338623537333332356231386438666565616537616538653465333431306638643961
3636663633363562320a613661313966376361396336383864656632376134353039663662666437
39393639343966363565636161316339643033393132626639303332373339376664
创建 create,加密 encrypt,解密 decript,编辑加密文件 edit,都可以通过 ansible-vault 进行:
ansible@smarthub-repo:~> ansible-vault
Usage: ansible-vault [create|decrypt|edit|encrypt|encrypt_string|rekey|view] [--help] [options] vaultfile.yml
当直接运行包含这些加密 vars 文件的 playbook 时,会出错(加密后的 vars 已经乱码了),要操作加密文件必须有密码保护,ansible 或 ansible-playbook 要加上 ask-vault-pass:
$ ansible-playbook site.yml --ask-vault-pass
或者创建一个.vault_pass 的文件,把密码放进去,让 Ansible 自动去读取:
$ echo "my_vault_password" > .vault_pass
$ ansible-playbook site.yml --vault-password-file=.vault_pass
记住在生存环境上创建这个文件.vault_pass,不要把它 commit 进 git 或 svn,否则人人都知道解密密码啦:
$ echo '.vault_pass' >> .gitignore
由于 Ansible 只能支持整个文件加密,所以如果把变量分成要加密的,不要加密的,就会破坏变量本事的结构,导致可读性变差,例如:
$ cat group_vars/database/vars
# nonsensitive data
mysql_port: 3306
mysql_host: 10.0.0.3
mysql_user: fred
# sensitive data
mysql_password: this_is_my_password
想要对 mysql_password 加密的话,要么对整个文件加密,要么把 mysql_password 移出到另一加密文件,但这都不是我们想要的,技巧是创建另一变量,通过引入来解决:
$ cat group_vars/database/vars
# nonsensitive data
mysql_port: 3306
mysql_host: 10.0.0.3
mysql_user: fred
# sensitive data
mysql_password: “{{ vault_mysql_password }}”
$ ansible-vault view group_vars/database/vault
vault_mysql_password: this_is_my_password
debug #
通过环境变量:
$ export ANSIBLE_STRATEGY=debug
或者直接在 playbook:
- hosts: localhost
strategy: debug
tasks:
-
当该任务出错时,Ansible 暂停执行,调用 debugger,这时可以查看或调整变量:
(debug) task.args
详细文档: https://docs.ansible.com/ansible/playbooks_debugger.html
另一个常用的方法时 debug module,拿来输出信息:
- name: display environment name
hosts: localhost
tasks:
- debug:
msg: "environment >>> {{ app_env }}"
verbosity:3
- name: display OS name
hosts: localhost
tasks:
- debug:
msg: "OS >>> {{ ansible_os_family }}"
verbosity:3
注意 verbosity,Ansible 命令行用 -v,-vv, -vvv, -vvvv 等来控制 debug 输出的 verbosity 程度,当 verbosity: 3 时,-v,-vv 时将看不到 debug 的输出。
其它运行技巧 #
把 ansible -playbook 匿名成 play,下面是几个有用的选项:
- play site.yml –list-tasks:列出所有的 tasks
- play site.yml –list-tags:列出所有的 tags
- play site.yml –syntax-check:做语法检查
- play site.yml –check :“虚假”运行,可告知那些 tasks 会产生改变,如果带上 -D or –diff,如果相关 module 支持,如 template,会显示前后改变的具体内容
- play site.yml –step:“单步”执行